
















RPA+AI如何防止大模型“幻觉”导致操作错误?2026年企业级可信智能体构建指南

在2026年,当企业将大模型(LLM)深度集成到RPA流程中以处理核心业务时,一个幽灵始终如影随形——“幻觉”(Hallucination)。它指的是AI模型自信地生成看似合理、实则完全错误或虚构的信息。对于需要精准执行的自动化操作而言,一次“幻觉”就可能导致数据错录、资金误付甚至合规事故。
那么,RPA+AI组合究竟是如何系统性地防范这一风险,确保操作万无一失的?答案在于:通过架构设计,将大模型从“自由创作者”转变为“受控执行者”。
一、为何RPA+AI是应对“幻觉”的天然解法?
单纯依赖大模型进行决策和操作是危险的。而RPA+AI的融合模式,其核心优势在于分离了“思考”与“执行”,并为“思考”过程施加了多重约束:
RPA的角色:作为忠实的“执行器”,只负责在明确指令下模拟人类操作,如点击、输入、上传等。它本身不具备“思考”能力,因此不会产生幻觉。
AI的角色:作为“智能大脑”,负责理解意图、解析非结构化数据(如发票、合同)、做出初步判断。但它的输出并非最终指令,而是待验证的“建议”。
这种分离,为引入防幻觉机制创造了完美的技术接口。
二、2026年主流的四大防幻觉技术策略
根据行业实践,成熟的RPA+AI平台主要通过以下四重机制来构筑防线:
基于知识库的事实锚定(Grounding)
原理:限制大模型只能在其训练数据之外,引用企业内部权威、实时的知识库(如产品目录、客户主数据、政策文件)来回答问题或做决策。
效果:从根本上杜绝了模型“凭空捏造”信息的可能性。例如,在回答客户关于某产品价格的问题时,AI必须从ERP系统中查询实时价格,而非依靠其记忆中的过时信息作答。
规则引擎的硬性约束
原理:将企业的业务规则、合规要求编码成不可逾越的“护栏”。无论大模型的推理结果如何,最终的操作指令都必须通过规则引擎的校验。
效果:即使AI因幻觉得出了错误结论,规则引擎也能将其拦截。例如,AI可能错误地认为一笔付款可以豁免审批,但规则引擎会强制检查金额阈值,确保流程合规。
人在回路(Human-in-the-Loop, HITL)
原理:对于高风险、低置信度或首次出现的场景,系统会自动暂停自动化流程,将AI的分析结果和建议推送给人工审核。
效果:这是最后一道安全阀。它不仅防止了错误操作,还将人类专家的反馈用于持续优化AI模型,形成良性循环。这在金融、政务等强监管领域尤为重要。
全流程可追溯与审计
原理:详细记录AI的每一次推理过程、所依据的数据源、生成的中间结果以及最终由RPA执行的操作。
效果:一旦出现问题,可以快速回溯定位是哪个环节出现了偏差(是数据源错误、提示词不当还是模型本身缺陷),从而精准修复,而非盲目信任或全盘否定AI。
三、案例佐证:从“聊天搭子”到“可信员工”
以某大型银行的应用为例:
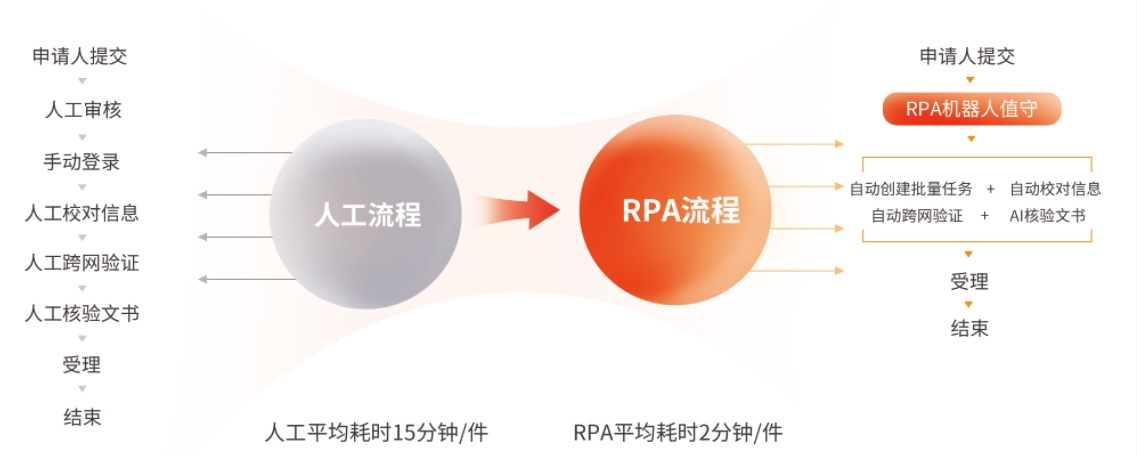
该行曾尝试用通用大模型直接处理信贷申请,结果因模型“幻觉”导致多份报告中的关键财务数据被篡改,险些造成重大损失。后引入金智维等厂商的RPA+AI方案,通过将大模型的输出严格限定在OCR识别和材料初筛环节,并将所有关键决策点交由内置的信贷规则引擎和人工复核,成功将操作错误率降至近乎为零,同时保留了AI带来的效率提升。
在2026年,企业对AI的要求已从“能说会道”转向“言出必行、行之有效”。RPA+AI的组合,通过事实锚定、规则约束、人机协同和全程审计这四大支柱,成功地将大模型的不确定性风险控制在可接受范围内,使其从一个充满魅力的“聊天搭子”,蜕变为一个值得信赖的“数字员工”。对于任何计划将AI引入核心业务流程的企业而言,这套系统化的防幻觉架构,是确保技术落地安全、可靠、有效的不二法门。


