















预训练语言模型如何操作?

在人工智能深度融入各行各业的2026年,预训练语言模型(Pretrained Language Models, PLMs)——如BERT、GPT、LLaMA、Qwen等——已成为自然语言处理(NLP)任务的核心基础设施。然而,许多开发者和企业用户仍对“如何实际操作这些模型”感到困惑:是直接调用API?还是需要本地部署?是否必须从头训练?本文将聚焦实操层面,系统梳理使用预训练语言模型的六大标准操作步骤,帮助你从零开始高效落地。
第一步:明确任务目标与模型选型
操作预训练语言模型前,需先回答两个关键问题:
你的任务是什么?
文本分类(如情感分析)
问答系统(如客服机器人)
文本生成(如写报告、写代码)
信息抽取(如实体识别、关系抽取)
机器翻译、摘要生成等
选择合适的预训练模型:
开源模型(Hugging Face提供):可本地部署、微调,数据可控;
商业API(如OpenAI、阿里百炼):开箱即用,但依赖网络且有调用成本。
通用大模型(如GPT-4、Qwen-Max):适合开放域生成、多轮对话;
领域专用模型(如BioBERT、Legal-BERT):在医疗、法律等垂直领域效果更优;
轻量级模型(如DistilBERT、TinyLLaMA):适合移动端或低算力环境;
开源 vs 闭源:
2026年建议:
若任务简单(如分类),优先尝试小参数开源模型+微调;若需强生成能力(如写营销文案),可直接调用大模型API。
第二步:获取模型与环境准备
1. 获取模型
方式一:通过Hugging Face Transformers库加载(推荐)
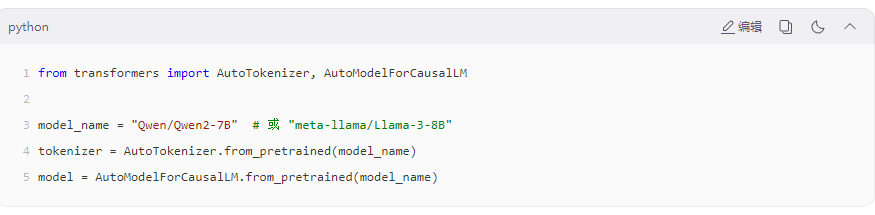
方式二:下载模型文件本地部署
访问Hugging Face Model Hub或魔搭(ModelScope);
下载pytorch_model.bin、config.json、tokenizer.json等文件;
放入本地目录,指定路径加载。
2. 环境配置
硬件:GPU(如A10、V100)加速推理;大模型需≥24GB显存;
软件:
Python ≥3.8
PyTorch / TensorFlow
transformers, accelerate, bitsandbytes(用于量化)
提示:2026年主流框架已支持一键量化(如GGUF、AWQ),可在消费级显卡(如RTX 4090)运行7B~13B模型。
第三步:数据准备与格式化
预训练模型需配合任务特定数据才能发挥价值。数据准备包括:
收集标注数据:
分类任务:(文本, 标签),如("这款手机很好", "正面")
生成任务:(输入, 目标输出),如("总结以下新闻...", "今日股市大涨...")
数据清洗:
去除噪声、特殊符号、重复样本;
统一编码格式(UTF-8);
截断超长文本(通常≤512 tokens)。
格式转换为模型输入:
使用Tokenizer将文本转为Token ID序列;
添加特殊标记(如[CLS], [SEP] for BERT;<|endoftext|> for GPT);
构建PyTorch Dataset对象。

第四步:微调(Fine-tuning)
注意:若仅使用大模型API(如调用GPT-4),此步可跳过。但微调能显著提升特定任务性能。
1. 选择微调策略
全参数微调:更新所有权重,效果最好,但显存消耗大;
参数高效微调(PEFT):
LoRA(Low-Rank Adaptation):仅训练低秩矩阵,节省90%显存;
Adapter:在Transformer层插入小型模块;
Prompt Tuning:只优化输入提示向量。
2. 配置训练参数
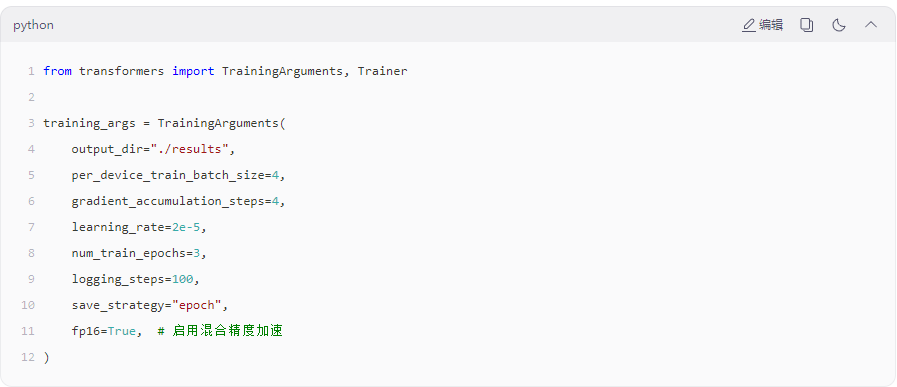
3. 启动训练
✅ 2026年最佳实践:
使用LoRA + 4-bit量化,可在单张消费级GPU上微调7B模型,训练时间缩短至数小时。

第五步:推理与部署
模型训练完成后,即可用于实际预测:
1. 本地推理示例
2. 部署方式选择| 方式 | 适用场景 | 工具 |
|---|---|---|
| 本地脚本调用 | 开发测试、小规模应用 | Python + Flask/FastAPI |
| Docker容器化 | 企业内部服务 | Docker + NVIDIA Triton |
| 云平台托管 | 高并发、弹性伸缩 | 阿里百炼、AWS SageMaker、Hugging Face Inference Endpoints |
| 边缘设备部署 | 手机、IoT设备 | ONNX Runtime、TensorRT |
趋势:2026年,Serverless AI推理成为主流——按调用量付费,无需管理服务器。
第六步:评估、监控与迭代
模型上线后需持续优化:
离线评估:
分类任务:准确率、F1值;
生成任务:BLEU、ROUGE、人工评分。
在线监控:
日志记录用户输入与模型输出;
检测异常响应(如幻觉、偏见);
A/B测试不同版本效果。
持续学习:
定期用新数据重新微调;
结合人类反馈强化学习(RLHF)优化生成质量。
操作预训练语言模型,重在“用”而非“造”
2026年,预训练语言模型的操作门槛已大幅降低。你无需从头训练千亿参数模型,也无需精通底层算法——掌握“选型→加载→微调→部署→迭代”的标准化流程,即可快速构建高价值AI应用。


