
















大语言模型的特点

在人工智能迈向通用智能的关键阶段,大语言模型(Large Language Model, LLM)已成为驱动技术革命与产业变革的核心基础设施。从智能客服到代码生成,从内容创作到企业决策,LLM 正以前所未有的能力重塑人机交互方式。那么,大语言模型究竟有哪些核心特点?本文将结合 2026 年最新技术进展,系统梳理其关键特性、能力边界与演进趋势。
一、什么是大语言模型?
大语言模型是一种基于深度神经网络(通常为 Transformer 架构)、在海量文本数据上进行预训练的 AI 模型。它通过学习语言的统计规律与语义结构,具备强大的文本理解与生成能力。典型代表包括 OpenAI 的 GPT 系列、Google 的 Gemini、Meta 的 Llama 系列、阿里云的通义千问(Qwen)、百度的文心一言、智谱的 GLM 等。
✅ 核心目标:
让机器“理解”人类语言,并以自然、连贯、有逻辑的方式进行回应或创作。
二、大语言模型的七大核心特点
1. 超大规模参数量
当前主流 LLM 参数量已达 数百亿至数千亿级(如 GPT-4 约 1.76 万亿稀疏参数);
更大的参数量意味着更强的知识容量与复杂任务处理能力;
但也带来更高的算力需求与推理成本。
2026 趋势:模型不再一味追求“更大”,而是通过混合专家(MoE)等架构实现“高效大模型”。
2. 强大的泛化能力(Generalization)
LLM 在预训练阶段接触了百科全书、新闻、代码、论文等多元数据;
因此即使面对未见过的任务或领域,也能通过上下文学习(In-context Learning)给出合理回答;
例如:从未专门训练过法律咨询,但能基于已有知识提供初步建议。
3. 上下文学习(In-context Learning)
无需微调模型,仅通过在输入中提供示例(Few-shot)或指令(Zero-shot),即可引导模型完成新任务;
示例:
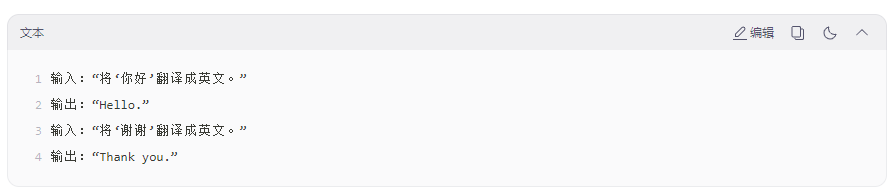
极大降低了 AI 应用的定制门槛。
4. 指令遵循能力(Instruction Following)
经过指令微调(Instruction Tuning)后,LLM 能准确理解并执行人类指令;
支持复杂指令如:“总结以下文章,用三点列出核心观点,语气正式,不超过200字”;
这是 LLM 从“聊天机器人”升级为“生产力工具”的关键。
5. 多语言与跨文化理解
主流 LLM 支持 100+ 种语言,包括中文、英文、阿拉伯语、斯瓦希里语等;
不仅能翻译,还能理解文化语境、习语、礼貌表达;
助力全球化企业实现本地化沟通与内容生成。
6. 工具调用与外部交互能力(Tool Use)
2026 年,先进 LLM 已不仅是“文本生成器”,更是智能代理(Agent)的核心;
可主动调用计算器、搜索引擎、API、数据库、RPA 工具等;
实现“思考 → 规划 → 执行 → 验证”的闭环,如自动订机票、分析财报、调试代码。
7. 持续进化与可扩展性
LLM 可通过持续预训练、人类反馈强化学习(RLHF/RLAIF)不断优化;
支持插件化扩展(如 Dify、LangChain 生态),灵活集成业务系统;
企业可基于开源基座模型(如 Llama 3、Qwen-Max)构建专属行业大模型。
三、LLM 的能力边界与挑战
尽管 LLM 能力强大,仍存在明显局限:
| 挑战 | 说明 |
|---|---|
| 幻觉(Hallucination) | 生成看似合理但事实错误的内容(如编造不存在的论文); |
| 时效性滞后 | 知识截止于训练数据时间点(如 GPT-4 截止 2023 年),需结合检索增强(RAG); |
| 推理深度有限 | 复杂数学证明、长链逻辑推理仍易出错; |
| 安全与伦理风险 | 可能生成偏见、违法或有害内容,需严格对齐(Alignment)机制; |
| 高成本部署 | 千亿级模型推理需昂贵 GPU 资源,推动轻量化与边缘部署需求。 |
四、2026 年 LLM 的演进方向
Agentic AI:LLM 作为“大脑”,驱动自主智能体完成多步任务;
多模态融合:与视觉、语音、传感数据结合,形成“全能感知”;
小型化与端侧部署:7B~13B 参数模型在手机、PC 上流畅运行(如 Qwen-Max、Phi-3);
可信 AI:引入事实核查、不确定性估计、可解释性模块;
行业深度定制:金融、医疗、制造等领域专属 LLM 成为企业标配。

大语言模型已从“技术奇观”转变为数字时代的新生产力工具。其核心特点——规模、泛化、指令理解、工具集成——共同构成了 AI 原生应用的基石。在 2026 年,理解 LLM 的能力与边界,不仅是技术人员的必修课,更是每一位管理者、创业者和内容创作者把握未来的关键。正如电力之于工业时代,大语言模型正成为智能时代的“新电力”。


