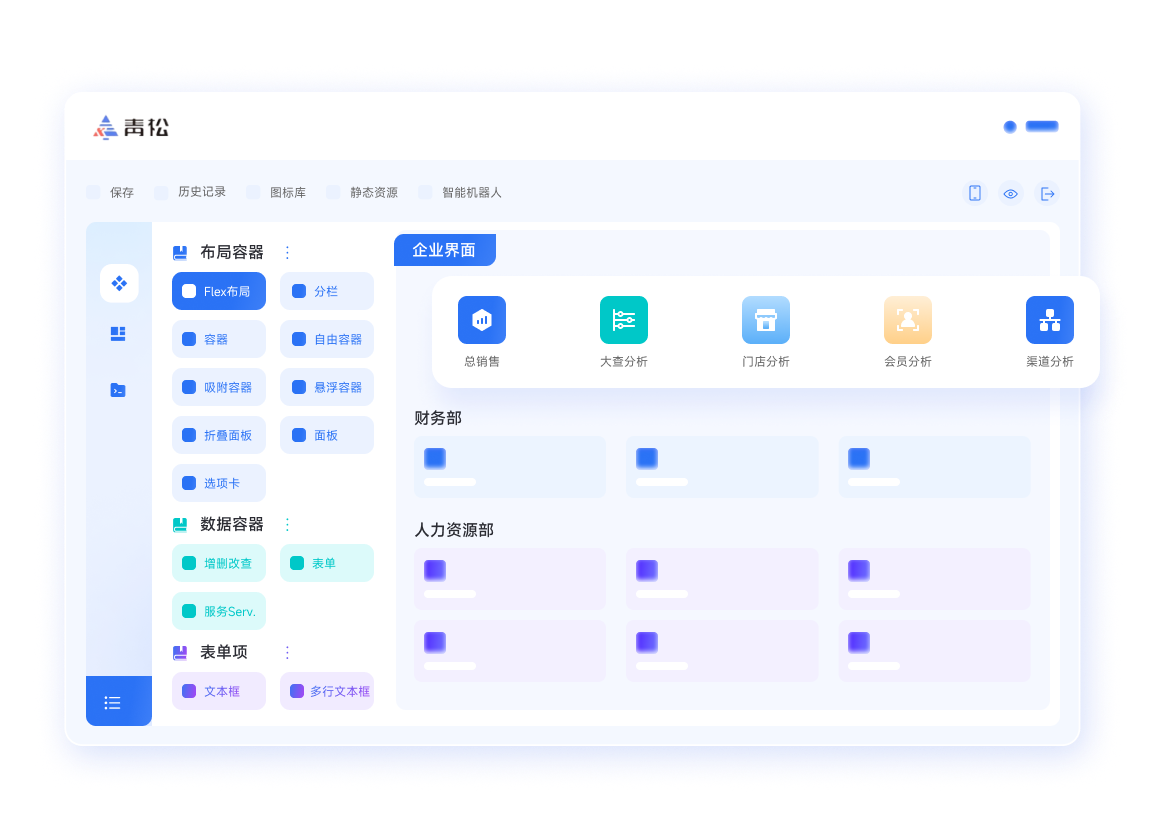
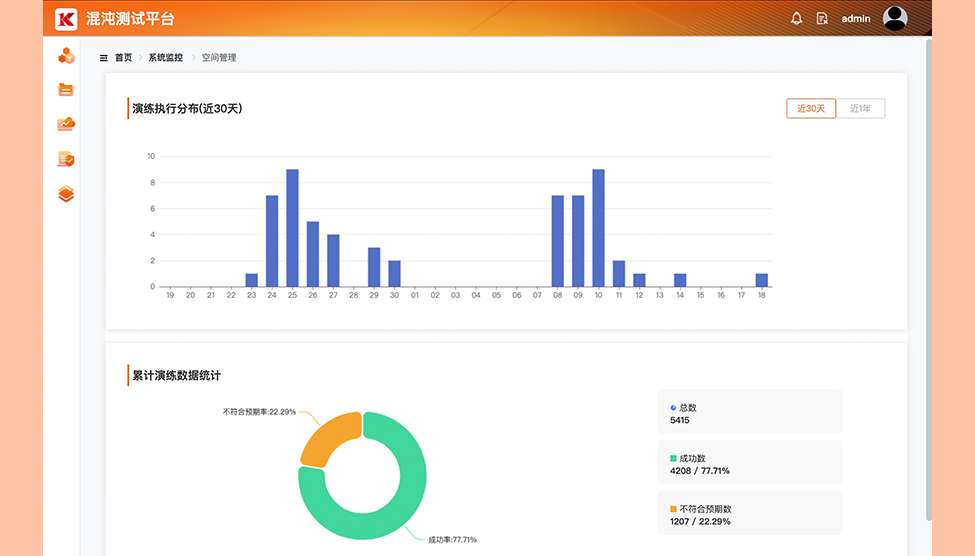
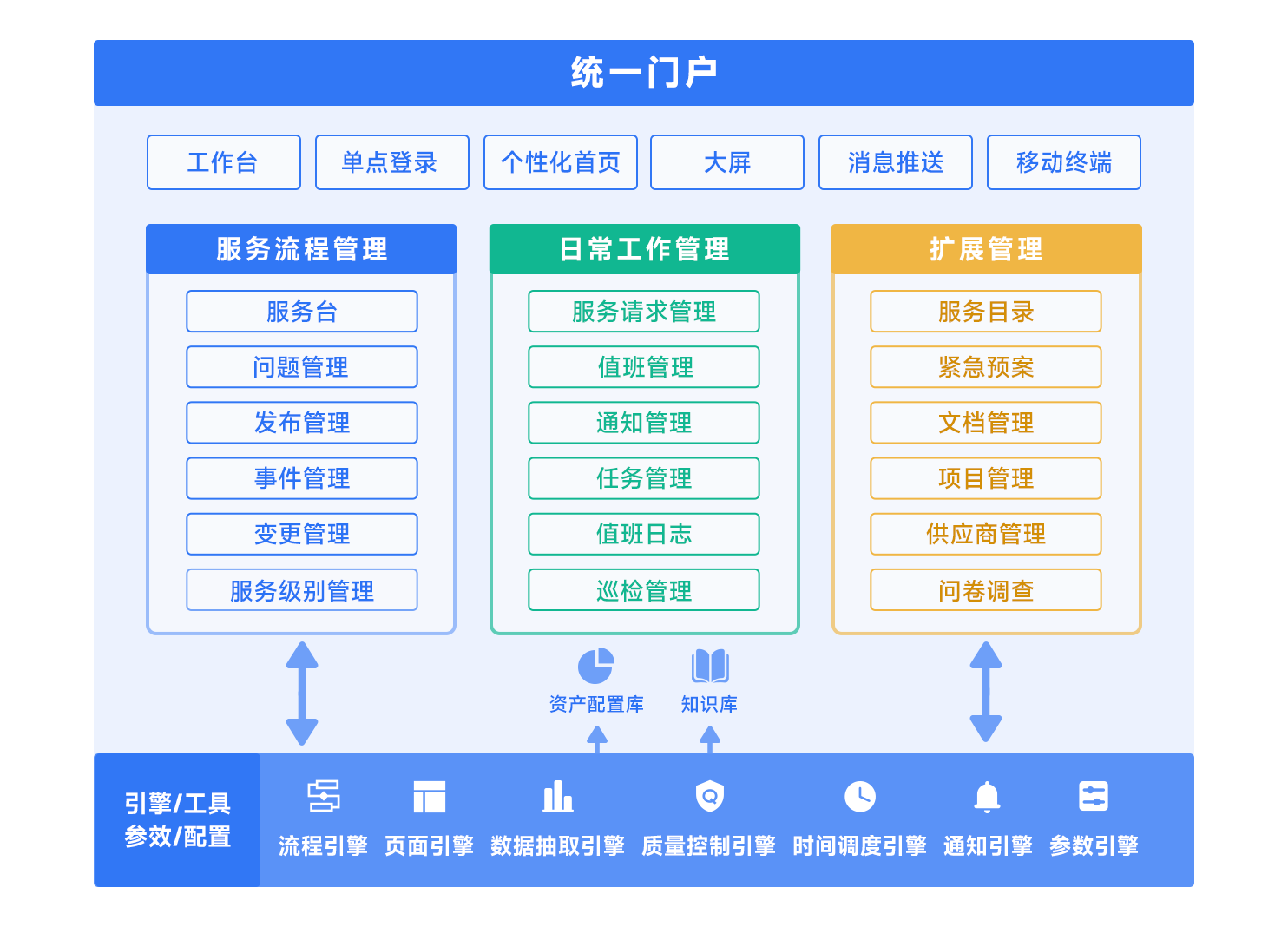
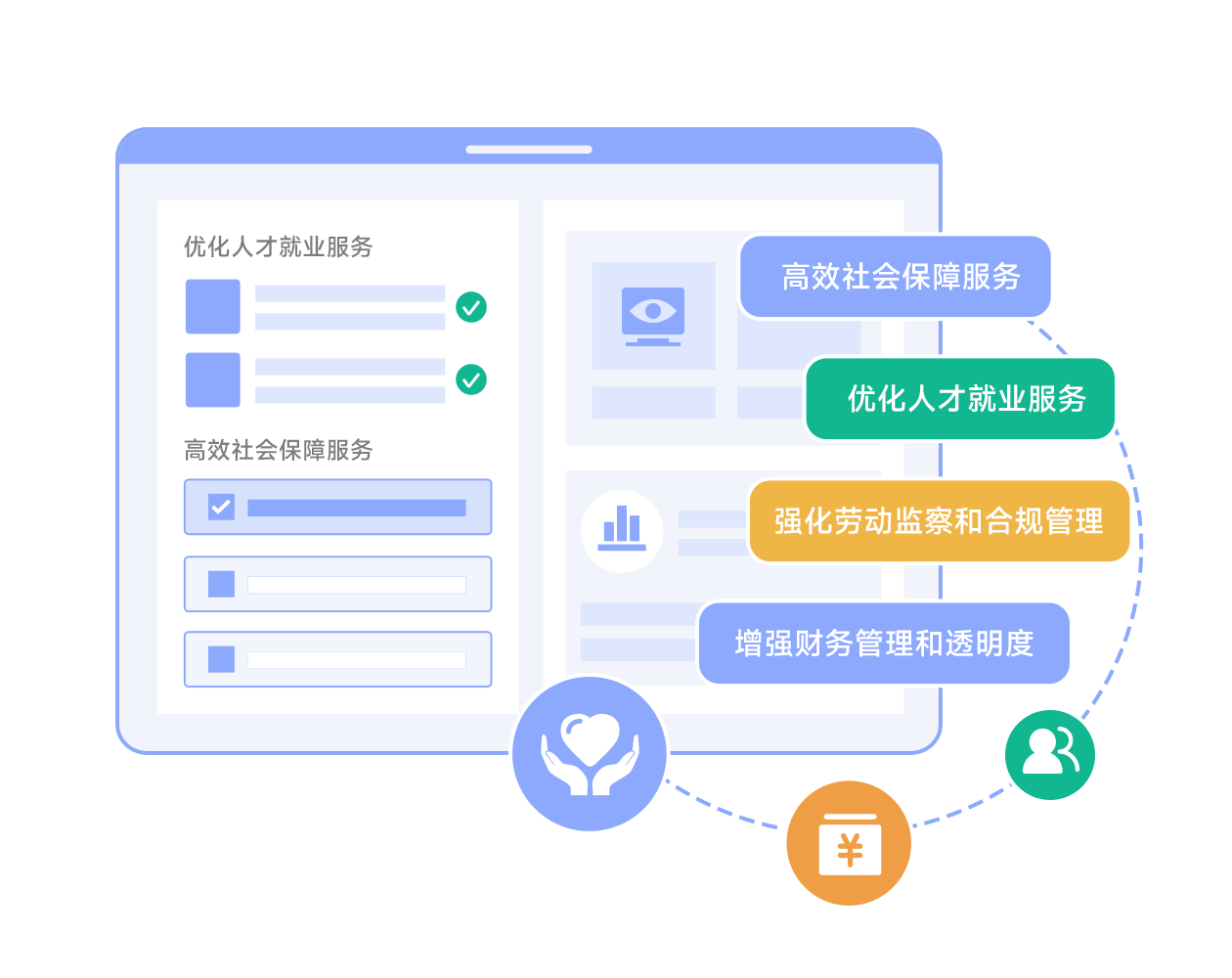
了解更多
企业开发各类业务系统时,传统方式常受限于高昂成本与漫长周期,难以快速响应多变的业务需求。低代码开发平台凭借可视化操作、组件化搭建的特性,无需大量编写代码就能高效构建应用,成为企业优化业务流程的得力工具。接下来,我们深入金融(银行、证券、基金)、政务、制造业领域,探索低代码的具体应用场景。
当下,企业应用的稳定、高效运行对于企业的日常运营和持续发展起着至关重要的作用。而建立一套完善的运维管理指标体系,是保障企业应用健康运转、及时发现和解决问题的关键所在。以下是企业应用运维管理指标体系搭建的全流程指南。
在多系统协同运行、业务流程高度耦合的现代企业中,告警系统早已不再是IT运维的“辅助工具”,而是保障业务连续性与风险可控的核心能力之一。然而,随着业务系统、云平台、微服务、DevOps等不断扩展,告警来源碎片化、标准不统一、信息冗余等问题日益凸显,传统分散式告警方式已无法支撑高效响应与统一治理需求。因此,构建一个统一的告警平台,成为保障业务连续性和风险可控的关键。
数字化基础设施高度复杂,企业运维面临的挑战不仅是系统数量的激增,更在于如何实现从“人盯人”的响应模式,向“自动协同”的智能化管理跃迁。构建一套标准化的自动化运维流程服务管理体系,成为提升IT运营效率、降低故障风险、支撑业务稳定的关键。许多企业在自动化建设初期,会陷入“工具替人”的误区:用脚本、定时任务或运维平台替代人工执行操作,却忽略了流程的统一管理和服务质量保障。结果是自动化能力分散、维护成本上升,故障排查更难。
财务管理系统,作为企业经营管控的核心系统之一,其导入和建设往往不是一项简单的IT项目,而是一项深度牵动组织、流程与制度的系统工程。从初期的业务需求梳理,到技术架构选型,再到上线后的持续优化与运维管理,每一个环节都关乎企业财务数字化水平的成败。财务管理系统从需求到落地有哪些关键步骤?每一阶段的关注重点与实施要点又是什么呢?只有弄清这些,企业才能少走弯路,高效实现系统上线与价值兑现。
企业数字化进程不断深入,财务系统的角色早已不再局限于“记账”与“核算”,而是逐渐演变为支撑企业高效运营和战略决策的核心平台。在实际业务中,财务系统往往需要与多种第三方平台进行数据交互,包括银行接口、税务申报平台、电商平台、支付平台、OA系统乃至外部审计系统。这类系统对接不仅关系到账务效率,更关系到企业信息安全和财务数据的合规流转。